
Firewalls, NATs y conexiones P2P – Guía para desarrolladores
Pablo Santos Luaces. Vicedecano CPIICyL
O “cómo agujerear NATs para conectar directamente aplicaciones que están tras diferentes firewalls”.
Hay muchos escenarios en los que es útil que dos procesos (aplicaciones de escritorio, web, apps móviles) se comuniquen entre sí a través de Internet.
La idea básica es sencilla: cada máquina tiene una dirección IP, uno de los dos procesos escucha en un puerto determinado y el otro se conecta a esa pareja ip:puerto.
Pero esto ya no es así de simple excepto cuando ambas aplicaciones estén en la misma LAN.
Lo habitual es que todo esté protegido tras su correspondiente firewall, que no se usen IPs públicas, y que por tanto conectar entre sí dos procesos no sea tan trivial como abrir un socket.
Pablo Santos Luaces. Vicedecano CPIICyL
O “cómo agujerear NATs para conectar directamente aplicaciones que están tras diferentes firewalls”.
Hay muchos escenarios en los que es útil que dos procesos (aplicaciones de escritorio, web, apps móviles) se comuniquen entre sí a través de Internet.
La idea básica es sencilla: cada máquina tiene una dirección IP, uno de los dos procesos escucha en un puerto determinado y el otro se conecta a esa pareja ip:puerto.
Pero esto ya no es así de simple excepto cuando ambas aplicaciones estén en la misma LAN.
Lo habitual es que todo esté protegido tras su correspondiente firewall, que no se usen IPs públicas, y que por tanto conectar entre sí dos procesos no sea tan trivial como abrir un socket.
Sin embargo, es posible establecer conexiones punto a punto (P2P) entre procesos a pesar de que estén protegidos por sus respectivos firewalls… y eso es lo que voy a explicar en este post. Está escrito en plan introducción, simplemente con la idea de presentar los conceptos para que luego cada uno pueda profundizar lo que necesite.
Si ya te suenan conceptos como STUN, TURN, ICE, relay… entonces no vas a aprender nada nuevo. En caso contrario… ¡¡te va a resultar muy interesante!!
Opciones para conectar dos procesos a través de Internet
Voy a hablar de “procesos” para referirme al software que queremos conectar a través de internet de forma directa. Esos procesos pueden ser aplicaciones de escritorio, apps móviles, web, servidores, etc.
Como decía en la introducción, la forma más sencilla de conectar dos procesos es con un socket (más fácil todavía de tipo stream, vamos TCP): uno escucha, y el otro se conecta. El cliente debe conocer la IP (o el nombre para obtener la IP) y el puerto del “servidor”.
El problema es que esto solo funciona si la IP del “servidor” es pública y si además la conoces de antemano.
Supongamos que lo que quieres hacer es una aplicación que envía ficheros entre dos ordenadores, lo más rápido posible, a través de internet. En tu sistema identificas a los usuarios por email (muy cómodo) de modo que de alguna forma quieres que pablo@cpiicyl.org pueda mandar un fichero a secretario@cpiicyl.org de forma directa.
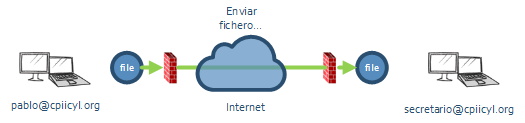
El problema es que “pablo” y “secretario” están cada uno en su casa, protegidos por sus respectivos firewalls, y no parece cómodo pedirles que abran puertos en su firewall para establecer la conexión (el port-forwarding del firewall al extremo que haga de servidor sería una opción, pero la descartamos por ser incómodo para el usuario).
Opción 1 – relay y TURN servers
Una opción es usar un servidor central, público en internet, que sirva de punto intermedio. Es lo que se conoce como “relay server”. Ambos procesos se conectan a él, negocian su intención de intercambiar datos, y el extremo “origen” sube los datos al relay, que los reenvía al “destino”. La comunicación se realiza a través de las conexiones “entrantes”. El servidor público no se conecta con nadie, ambos extremos se conectan con él y él aprovecha el socket abierto con cada usuario para realizar el envío.
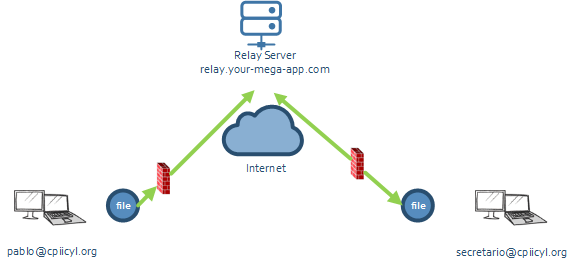
En el caso de nuestro ejemplo: pablo@cpiicyl.org quiere enviar un fichero a “secretario”. “pablo” se conecta con el “relay server” indicando su intención de enviar el fichero.
El relay server comprobará si “secretario” está ya conectado con él. Si no lo está, contestará a “pablo” con un error.
Si sí que está, el servidor enviará un mensaje a “secretario” por el socket que tiene abierto con él, indicando que “pablo” le quiere enviar un fichero. Todo esto es implementación de un protocolo propio, muy sencillo, para establecer las conexiones, claro, simplemente unos pocos bytes enviados por el socket. Una vez ambos están “listos”, el proceso ejecutado por “pablo” sube el fichero al servidor, y este lo reenvía a “secretario” por el socket que ya tenía abierto con él (como antes para indicarle que la conexión iba a comenzar).
El caso es que además de poder implementarte tu propio sistema en un momento, existe ya un protocolo llamado TURN (https://en.wikipedia.org/wiki/Traversal_Using_Relays_around_NAT) o Traversal Using Relays around NAT que hace justo esto que acabamos de ver, lo que pasa es que es un estándar, hay un RFC que cuenta cómo implementarlo, etc.
La idea en sí es muy sencilla. Lo interesante, en mi opinión, es saber que a esto se le llama “relay” y que el protocolo que ya existe se llama TURN, de modo que, si tienes que implementar algo parecido, no reinventes la rueda (o lo hagas, pero con conocimiento de causa).
Todo esto del TURN se usa mucho para VoIP, igual que el resto de conceptos de este artículo, aunque no es exclusivo y se puede usar para otros fines.
Opción 2 – conexión directa – NAT hole punching
Con los relays que acabamos de ver simulamos una conexión directa, pero estamos usando un proceso intermedio, con el coste añadido en dinero (el tráfico de ese ordenador tiene un coste si está en Amazon, Azure, etc) y en tiempo: doble salto.
¿Es posible hacer una conexión directa entre dos procesos si ambos están tras un firewall?
Una forma, como ya dije antes, es abrir puertos en el firewall y establecer redirecciones. Esto se puede hacer a mano o se puede programar con UPNP y PMP, es decir, tu programa puede pedirle al firewall que abra un puerto y haga una redirección pero… yo no he encontrado ningún firewall/router que lo haga de serie, con lo cual es muy difícil que uno de nuestros usuarios vaya a tenerlo. (En su día hicimos pruebas con Open.NAT, una librería en Mono/C# https://github.com/lontivero/Open.NAT).
La otra opción es el “NAT hole punching”. Vamos, “agujerear” el firewall para que nos deje establecer conexiones P2P.
La idea suena rara la primera vez, pero es muy sencilla:
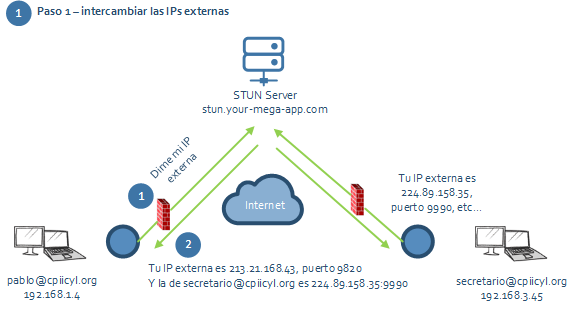
Al final hay un servidor intermedio que sirve para compartir las direcciones públicas de cada proceso (combinación IP pública:puerto). Ese servidor intermedio ayuda a cada proceso a descubrir su IP externa y el puerto que el firewall está usando, que normalmente es el mismo que tu puerto local.
Entonces ocurre lo interesante:
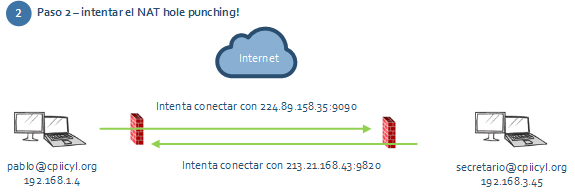
- Cada extremo intenta conectar con la IP:puerto del otro. Ojo, cada uno de ellos hace un bind para reutilizar el mismo puerto local que usó para establecer la conexión con el servidor central en primer lugar. Si no se hace eso, el router/firewall no usará la misma combinación ip/puerto y por tanto rechazará cualquier paquete entrante.
- Como el router ya tenía tráfico “saliente” por esos puertos, es muy posible (nótese lo de posible, que no siempre funciona) que permita tráfico entrante.
- Si eso ocurre, ambos procesos se habrán conectado de forma directa a pesar de estar ambos detrás de sus respectivos firewalls y de no tener IPs públicas propias.
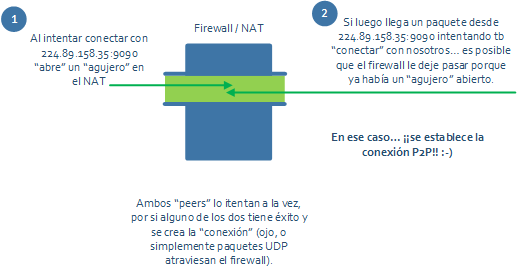
El truco está en el “bind” que cada cliente hace de nuevo al mismo puerto local con el que estableció la conexión con el servidor intermedio. Al volver a hacer el mismo bind contra el mismo puerto para conectarnos con el peer remoto, sabemos que se va a mantener (con mucha probabilidad) el mismo mapping del NAT, y que por tanto la ip:puerto público que hemos compartido con el otro peer se mantendrá.
Los firewalls más seguros no permitirán hacer esto porque “sabrán” que el paquete entrante no viene del origen contra el que se estableció la conexión, y no se dejarán engañar con otro origen diferente que intenta reutilizar el mismo puerto/ip para conectar con el proceso interno.
Es importante destacar que es diferente el UDP hole punching del TCP. En general, el UDP casi siempre funciona y el TCP está más restringido, por la propia implementación del protocolo.
En UDP ocurre prácticamente lo que he contado antes, y que explico aquí con código muy sencillo en C# usando la librería UDT, que ya hace “NAT Traversal” usando el flag RENDEZVOUZ (se podría hacer algo parecido con UDP directamente, pero muestro un ejemplo de código con UDP, librería para envío masivo de datos en redes de alta latencia):
class Client
{
public static void Run(string[] args)
{
if (args.Length < 3)
{
Console.WriteLine(«Usage: {0} client local_port server server_port [client|server]»,
System.AppDomain.CurrentDomain.FriendlyName);
return;
}
Udt.Socket client = new Udt.Socket(AddressFamily.InterNetwork, SocketType.Stream);
client.ReuseAddress = true;
client.Bind(IPAddress.Any, int.Parse(args[0]));
IPAddress serverAddress;
if (!IPAddress.TryParse(args[1], out serverAddress))
{
Console.WriteLine(«Error trying to parse {0}», args[1]);
return;
}
client.Connect(serverAddress, int.Parse(args[2]));
int peerPort;
IPAddress peerAddress;
// recv the other peer info
using (Udt.NetworkStream st = new Udt.NetworkStream(client, false))
using (BinaryReader reader = new BinaryReader(st))
{
int len = reader.ReadInt32();
byte[] addr = reader.ReadBytes(len);
peerPort = reader.ReadInt32();
peerAddress = new IPAddress(addr);
Console.WriteLine(«Received peer address = {0}:{1}»,
peerAddress, peerPort);
}
bool bConnected = false;
int retry = 0;
while (!bConnected)
try
{
client.Close();
client = new Udt.Socket(AddressFamily.InterNetwork, SocketType.Stream);
client.ReuseAddress = true;
client.SetSocketOption(Udt.SocketOptionName.Rendezvous, true);
client.Bind(IPAddress.Any, int.Parse(args[0]));
Console.WriteLine(«{0} – Trying to connect to {1}:{2}. «,
retry++, peerAddress, peerPort);
client.Connect(peerAddress, peerPort);
Console.WriteLine(«Connected successfully to {0}:{1}»,
peerAddress, peerPort);
bConnected = true;
}
catch(Exception e)
{
Console.WriteLine(e.Message);
}
if (args[3] == «client»)
{
using (Udt.NetworkStream st = new Udt.NetworkStream(client))
using (BinaryReader reader = new BinaryReader(st))
{
w
hile (true)
{
Console.WriteLine(reader.ReadString());
}
}
}
else
{
using (Udt.NetworkStream st = new Udt.NetworkStream(client))
using (BinaryWriter writer = new BinaryWriter(st))
{
int last = Environment.TickCount;
while (!Console.KeyAvailable)
{
if (Environment.TickCount – last < 1000)
continue;
writer.Write(string.Format(«[{0}] my local time is {1}»,
Environment.MachineName, DateTime.Now.ToLongTimeString()));
last = Environment.TickCount;
TraceInfo traceInfo = client.GetPerformanceInfo();
Console.WriteLine(«Bandwith Mbps {0}», traceInfo.Probe.BandwidthMbps);
}
}
}
}
}
}
Si os dais cuenta ambos hacen un “connect” y nadie está haciendo un “listen()”.
En el caso de TCP se suele hacer lo siguiente:
- Se produce el intercambio.
- Cada proceso intenta a la vez conectar y hacer un listen en el mismo puerto, y el primero que funcione tendrá una conexión abierta.
En TCP también se puede hacer funcionar con ambos lados intentando hacer un “connect”, algo que en condiciones normales nunca funcionaría porque uno de los dos debería estar haciendo un “accept”.
El siguiente código es simplemente un fragmento que asume que ya se ha obtenido la ip:puerto público del “peer” con el que se quiere conectar. Una vez la conexión está realizada, uno de los peers envía datos y el los recibe.
// open a hole, try co connect to peer
bool bConnected = false;
try
{
_connectSocket = new Socket(AddressFamily.InterNetwork, SocketType.Stream, ProtocolType.Tcp);
_connectSocket.SetSocketOption(SocketOptionLevel.Socket, SocketOptionName.ReuseAddress, true);
_connectSocket.SetIPProtectionLevel(IPProtectionLevel.Unrestricted);
_connectSocket.ExclusiveAddressUse = false;
_connectSocket.Bind(_clientSocket.LocalEndPoint);
IPEndPoint iep = remoteEndPoint;
_connectSocket.Connect(iep);
Console.WriteLine(«ClientRequest: Connected correctly with: » + iep);
bConnected = true;
}
catch(Exception e)
{
Console.WriteLine(
«Trying to open a hole. Caught exception, but hole probably opened. {0} {1}»,
e.Message, e.StackTrace);
}
while (!Console.KeyAvailable)
{
try
{
if (!bConnected)
{
Console.WriteLine(«Client trying to connect. Press a key to cancel»);
IPEndPoint iep = (IPEndPoint)remoteEndPoint;
_connectSocket.Connect(iep);
Console.WriteLine(«ClientRequest: Connected correctly with: » + iep);
bConnected = true;
}
if (mRole == «sender»)
{
Console.WriteLine(«Going to read from the server side»);
NetworkStream networkStream = new NetworkStream(_connectSocket);
BinaryWriter writer = new BinaryWriter(networkStream);
int last = Environment.TickCount;
while (!Console.KeyAvailable)
{
if ((Environment.TickCount – last) < 1000)
continue;
writer.Write(string.Format(«[{0}] this is {1}»,
DateTime.Now.ToLongTimeString(), Environment.MachineName));
last = Environment.TickCount;
}
}
else
{
NetworkStream st = new NetworkStream(_connectSocket);
BinaryReader reader = new BinaryReader(st);
; Console.WriteLine(«Connection set, press a key to exit»);
while (!Console.KeyAvailable)
{
Console.WriteLine(reader.ReadString());
}
}
}
catch (Exception e)
{
Console.WriteLine(
«Trying to connect. Sleeping. {0} {1}»,
e.Message, e.StackTrace);
System.Threading.Thread.Sleep(1000);
}
}
NAT hole punching estandarizado – STUN servers
Lo anterior es la forma “hacker” (vamos, tampoco tanto, que al final los firewalls lo tienen previsto) de hacer hole punching, pero ya hay también estándares (también relacionados con VoIP) para hacer esto mismo.
Se llama STUN server (Session Traversal Utilities for NAT – https://en.wikipedia.org/wiki/STUN) a esos servidores que sirven para descubrir las IPs públicas. Y se llama STUNT (http://nutss.gforge.cis.cornell.edu/stunt.php) a lo mismo pero para TCP.
Hay servidores STUN e incluso servicios STUN (https://gist.github.com/zziuni/3741933) de modo que es posible que no sea necesario desarrollar uno nuevo, y del mismo modo hay librerías cliente STUN para la mayoría de lenguajes.
Incluso hay un protocolo definido para todo este proceso que se denomina ICE (Interactive Connectivity Establishment) https://en.wikipedia.org/wiki/Interactive_Connectivity_Establishment.
Conclusión
Como decía al principio, este artículo solamente pretende realizar una introducción de alto nivel y compartir algunos conceptos interesantes para evitar “reinventar la rueda” si nos enfrentamos al problema de conectar dos procesos a través de diferentes firewalls.
Ahora conceptos como STUN, TURN, relay, NAT hole punching e incluso ICE ya no nos sonarán como algo ajeno…
Post a Comment
Lo siento, debes estar conectado para publicar un comentario.